
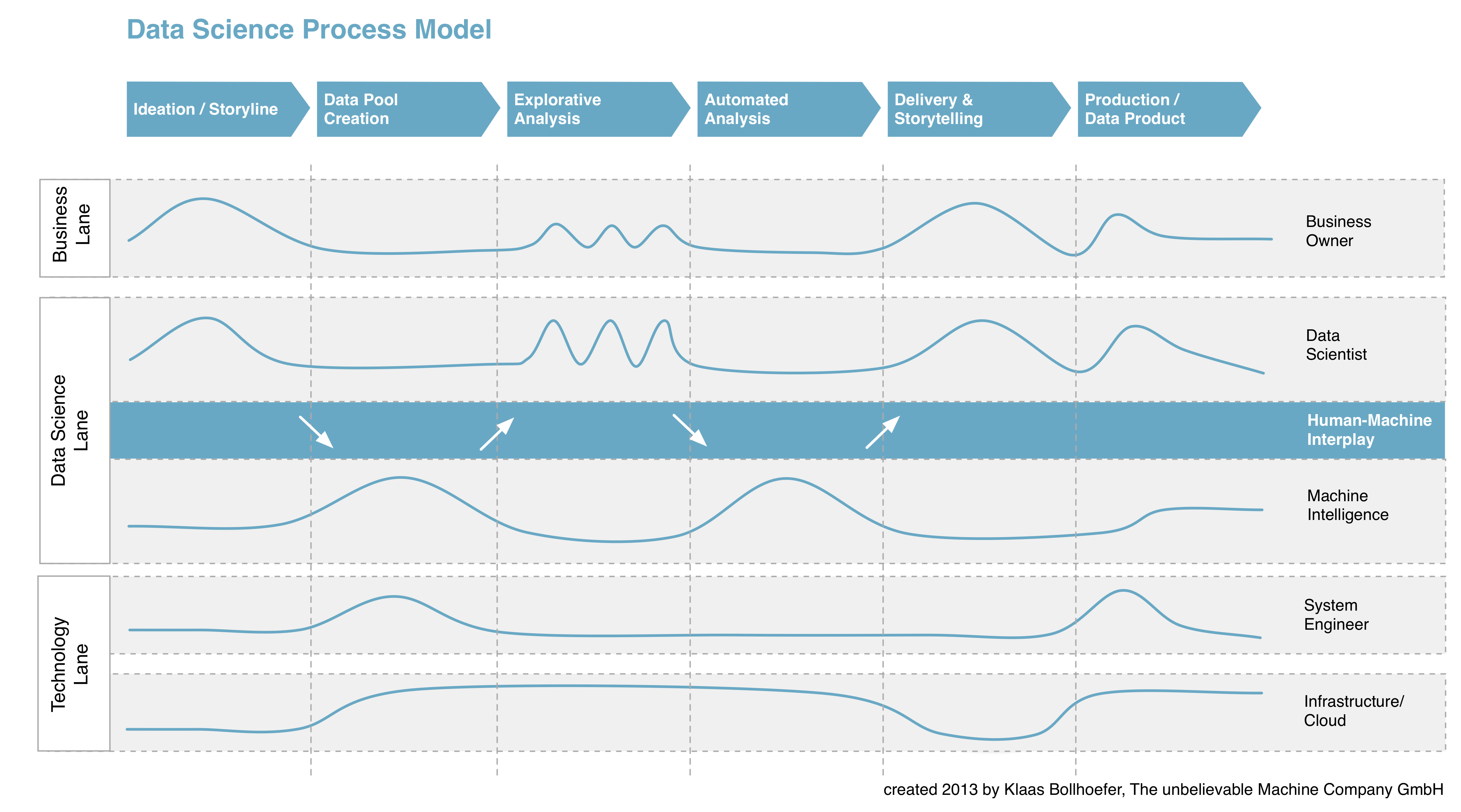
Das Data Science Process Model – Leitfaden zur Realisierung von Big Data-Produkten
Ein Gastbeitrag von Klaas Bollhoefer. Das Data Science Process Model ist ein Vorgehensmodell, das den Prozess zur Entwicklung von Big Data-Produkten in sechs definierte Phasen organisiert und die einzelnen Akteure und ihr Zusammenspiel darin darstellt. Kern des Modells ist das harmonische Wechselspiel der Akteure Data Scientist und Machine Intelligence, die nahtlose Verknüpfung menschlicher und maschineller Intelligenz im Rahmen explorativer und automatisierter Big Data-Analysen. Das Data Science Process Model ist international eines der ersten, aus der Praxis hervorgegangenen Vorgehensmodelle -vielleicht sogar die erste theoretische Darstellung überhaupt – und soll einen Beitrag zur weiteren Standardisierung der Disziplin leisten. Als Leitfaden kann es der individuellen Planung und Aufwandskalkulation bei der Realisierung von Big Data-Produkten dienen. Entwickelt habe ich das Modell bei The unbelievable Machine Company. Es basiert auf den Erkenntnissen und Erfahrungen aus einer Vielzahl von Big Data-Projekten für unterschiedliche Branchen und Fachdomänen aus den Jahren 2011-2013. Schematische Darstellung Zur Vergrößerung Grafik anklicken: Beschreibung der einzelnen Phasen Das Data Science Process Model besteht aus sechs aufeinander folgenden Phasen und beschreibt damit den Gesamtprozess zur Entwicklung von Big Data- Lösungen – …
