
Ein Gastbeitrag von Klaas Bollhoefer.
Das Data Science Process Model ist ein Vorgehensmodell, das den Prozess zur Entwicklung von Big Data-Produkten in sechs definierte Phasen organisiert und die einzelnen Akteure und ihr Zusammenspiel darin darstellt.
Kern des Modells ist das harmonische Wechselspiel der Akteure Data Scientist und Machine Intelligence, die nahtlose Verknüpfung menschlicher und maschineller Intelligenz im Rahmen explorativer und automatisierter Big Data-Analysen.
Das Data Science Process Model ist international eines der ersten, aus der Praxis hervorgegangenen Vorgehensmodelle -vielleicht sogar die erste theoretische Darstellung überhaupt – und soll einen Beitrag zur weiteren Standardisierung der Disziplin leisten. Als Leitfaden kann es der individuellen Planung und Aufwandskalkulation bei der Realisierung von Big Data-Produkten dienen.
Entwickelt habe ich das Modell bei The unbelievable Machine Company. Es basiert auf den Erkenntnissen und Erfahrungen aus einer Vielzahl von Big Data-Projekten für unterschiedliche Branchen und Fachdomänen aus den Jahren 2011-2013.
Schematische Darstellung
Zur Vergrößerung Grafik anklicken:
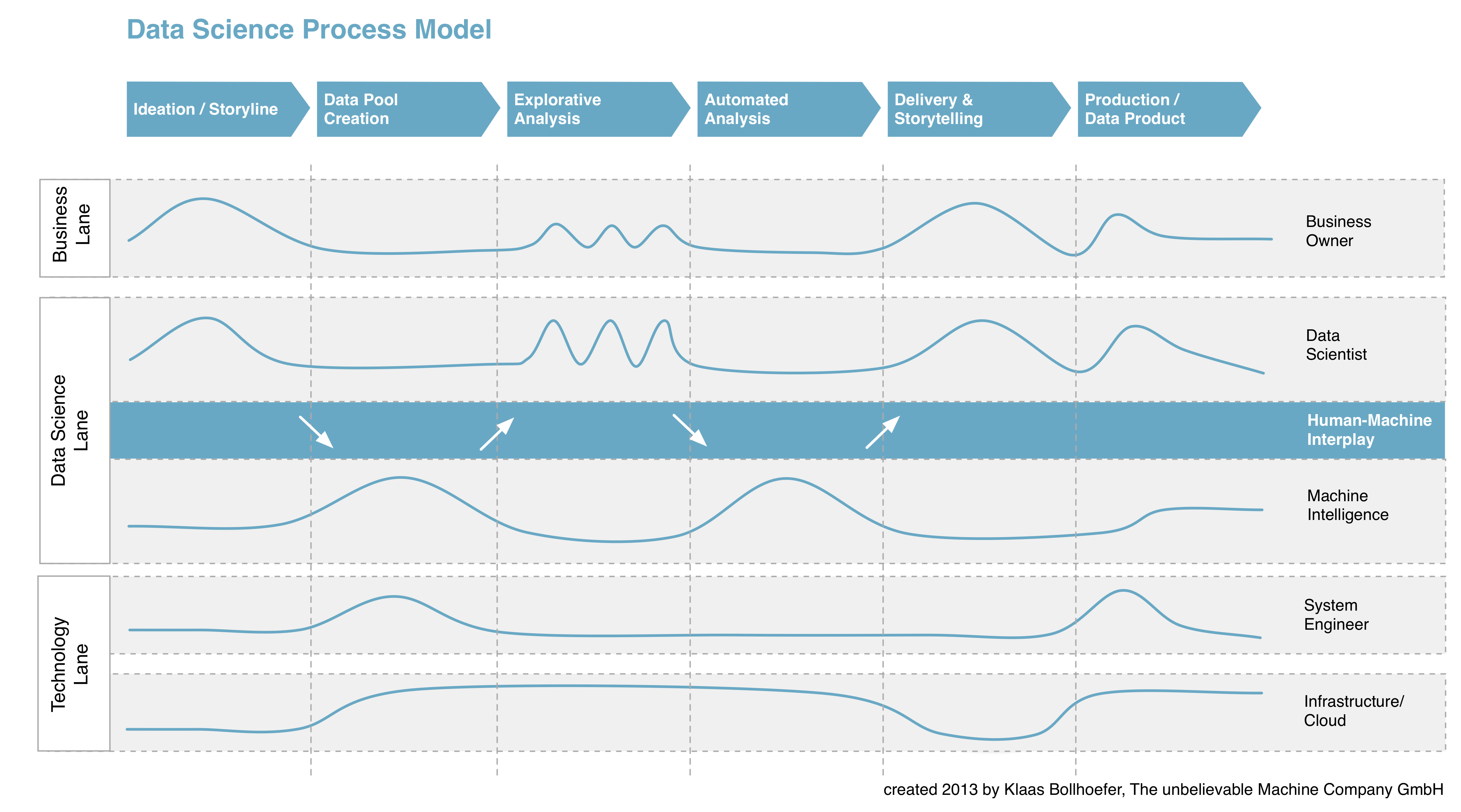
Beschreibung der einzelnen Phasen
Das Data Science Process Model besteht aus sechs aufeinander folgenden Phasen und beschreibt damit den Gesamtprozess zur Entwicklung von Big Data- Lösungen – von der ersten Idee bis zum Betrieb eines Data Products. Es geht damit über einen reinen Software-Entwicklungsprozess hinaus und verbindet Phase für Phase die Endpunkte Business und Technologie.
Ideation/Storyline
Anforderungen an eine Big Data-Lösung werden in Form von Fragen, Wünschen und Ideen im Team aus Business Owner und Data Scientist entwickelt und dokumentiert – die „Storyline“ für das Data Product. Gemeinsam werden Datenquellen identifiziert und für das weitere Vorhaben ausgewählt.
Data-Pool-Creation
Identifizierte Datenquellen – Web/Social, Open Data, Enterprise Data – werden in Data Pools zusammengeführt und bilden die Basis für nachfolgende Analysen. Die Daten durchlaufen dabei zahlreiche Prozessschritte – Data Access & Import, Data Cleaning & Normalisierung, Data Splitting & Aggregation. Die einzelnen Prozessschritte lassen sich je Quellsystem häufig automatisiert durchführen.
Explorative Analysis
Die Phase der explorativen Analysen bildet das Kernstück des Data Science- Vorgehensmodells. Im Wechselspiel und in enger Verzahnung mit dem Akteur Machine Intelligence entwickelt der Data Scientist mit seinem Toolkit aus Algorithmen, Verfahren und Programmen iterativ das Konzept für das geplante Data Product. Nach jeder Iteration erfolgt in Abstimmung mit dem Business Owner eine Validierung und (Re-)Fokussierung der Storyline. In Bezug auf Planbarkeit ist diese Phase „of uncertainties and wonders“ am diffizilsten; iterative Planungsmodelle (bspw. Sprints & Reviews) leisten hier gute Dienste.
Automated Analysis
Automatisierte Analysen sorgen für den „scale out“, die Anwendung intelligenter Verfahren auf beliebig große, beliebig strukturierte oder beliebig schnelllebige Data Pools. Dies ist die Phase, in der die „Maschinen“ dem Data Scientist die meiste Arbeit abnehmen und in der auch Technologien wie Hadoop & Co. ihren Auftritt im großen Stil haben.
Delivery & Storytelling
In dieser Phase werden die Ergebnisse der Analysen bereitgestellt und präsentiert. Dies kann zum einen die technische Bereitstellung („for machines“), zum anderen die zielgruppenadäquate Aufbereitung & Darstellung der Ergebnisse in Richtung Business Owner und nicht zuletzt Endnutzer/Konsument bedeuten („for humans“).
Production / Data Product
Den Abschluss des Phasenmodells bildet die Überführung des Data Products in den Regelbetrieb der Unternehmung.
Beschreibung der Akteure
Die Akteure, die im Data Science Process Model involviert sind, lassen sich in drei sogenannte „Swim Lanes“ organisieren – Business Lane (Business Owner), Data Science Lane (Data Scientist, Machine Intelligence), Technology Lane (System Engineer, Infrastructure/Cloud). Die „Pulse Lines“ symbolisieren als Aktivitätsmaß die Relevanz und Teilnahme eines Akteurs in der jeweiligen Phase.
Business Owner
Der Business Owner besitzt relevantes Domänen- und Branchenwissen. Je nach Projekt handelt es sich um ganz unterschiedliche Personen, oft auch um eine Personengruppe. Der Endnutzer/Konsument eines Data Products gilt nach diesem Model später ebenfalls als Business Owner.
Data Scientist
Der Data Scientist begleitet das Vorgehen von Anfang bis Ende über alle Phasen. Er unterstützt den Business Owner in der Anforderungsdefinition, kreiert mit Hilfe explorativer und automatisierter Analysen im Wechselspiel mit Machine Intelligence das Konzept für das Data Product, sorgt für die projektspezifische Bereitstellung der Ergebnisse und begleitet Business Owner und Data Product in den Regelbetrieb. Er ist Begleiter, Planer & „Bändiger der Maschinen“.
Machine Intelligence
Machine Intelligence dient als Sammelbegriff für eine Vielzahl an Algorithmen, Verfahren und Programmen, die im Rahmen der Data Pool Creation und der explorativen & automatisierten Analysen zum Einsatz kommen.
System Engineer
Der System Engineer steht stellvertretend für Rollen aus den Bereichen Softwareentwicklung, IT/System Architektur und Datenbankadministration. Er sorgt für die Konfiguration, Adaption, Entwicklung und den Betrieb von Big Data- Lösungen.
Infrastructure/Cloud
Die Begriffe Infrastructure/Cloud repräsentieren hier die gesamte IT-Systemlandschaft im Rahmen eines Big Data-Projekts.
 Klaas Bollhoefer arbeitet bei *um – The unbelievable Machine Company in Berlin, einem Spezialisten für Big Data, Cloud Computing & Web Operations. Er ist Initiator des Data Science Day und an der Organisation zahlreicher internationaler Big-Data-Veranstaltungen beteiligt. Für das oreillyblog berichtete er zuletzt aus dem Leben eines Datenforschers.
Klaas Bollhoefer arbeitet bei *um – The unbelievable Machine Company in Berlin, einem Spezialisten für Big Data, Cloud Computing & Web Operations. Er ist Initiator des Data Science Day und an der Organisation zahlreicher internationaler Big-Data-Veranstaltungen beteiligt. Für das oreillyblog berichtete er zuletzt aus dem Leben eines Datenforschers.
Ein paar interessante Bücher für amtierende und angehende Datenjongleure:
Data Analysis with Open Source Tools
Datenanalyse von Kopf bis Fuß
Lean Analytics
Beautiful Data
Bad Data Handbook
Hadoop – The Definitive Guide
Hadoop Operations
Programming Hive
MapReduce Design Patterns