
Unser Übersetzer Dr. Kristian Rother blickt in diesem Gastbeitrag unter die Motorhaube eines didaktisch sinnvollen Buchaufbaus – am Beispiel der Python-Bibliothek pandas im Buch „Datenanalyse mit Python“.
Woran erkennt man einen ausgezeichneten technischen Text? Meiner Meinung nach an der universellen Anwendbarkeit, über die eigentlich beschriebene Technologie hinaus.
Beim Übersetzen des Buches “Datenanalyse mit Python” von Wes McKinney bin ich auf zahlreiche Beispiele dafür gestoßen. Im Buch wendet Wes eine bestimmte didaktische Struktur an, um universelle Anwendbarkeit zu erreichen.
Da ich die gleiche didaktische Struktur selbst im Training einsetze, und außerdem Wes’ Inhalte verwende, stelle ich diese hier einmal vor. Es handelt sich dabei um die Kombination der drei Komponenten Technologie, Daten und Problemstellung.
Die Technologie
Logisch, dass ein technischer Text sich mit mindestens einer Technologie auseinandersetzt. In “Datenanalyse mit Python” ist das die Python-Bibliothek pandas. pandas stellt eine mächtige Datenstruktur für tabellarische Daten bereit. Ich erinnere mich an meine ersten Versuche, Tabellen in Python zu bearbeiten. Ohne pandas hatte ich die Wahl zwischen verschachtelten Listen, verschachtelten Dictionaries, Listen in Dictionaries, Dictionaries in Listen usw. Nichts davon funktionierte so richtig zufriedenstellend. Das Tabellenformat in pandas ist an die DataFrames aus dem Statistikprogramm R angelehnt. Das verkürzt den Code ganz erheblich und bietet sehr viele Möglichkeiten, effizient mit Daten zu arbeiten. So viele, dass sich bequem ein ganzes Buch dazu füllen ließ.
Die Erklärung der Technologie eignet sich schon einmal zum selbst Ausprobieren. Zum Beispiel analysiert Wes McKinney in Kapitel 2 die Namen aller seit 1880 in den USA geborenen Babys mit pandas. Mit zwei Zeilen Python-Code lassen sich die häufigsten 1000 Namen für jede Kombination von Name und Geschlecht berechnen:
for year, group in names.groupby(['year', 'sex']): pieces.append(group.sort_index(by='births', ascending=False)[:1000])
Diese Art von Codebeispiel zeigt natürlich, dass wir es bei Wes McKinney mit einem Mozart der Datenanalyse zu tun haben. Die Virtuosität des Autors wurde mir spätestens dann klar, als ich beim Nachkochen das Beispiel erst einmal in mehrere einfachere Python-Zeilen zerlegen musste.
Allein mit der Technologie ist die universelle Anwendbarkeit jedoch noch nicht gegeben. Ein Buch zur Python-Bibliothek pandas beschreibt erst einmal nur diese. Da wir davon ausgehen können, dass sich Technologien ständig entwickeln, unterliegt eine rein technische Beschreibung einer gewissen Halbwertszeit.
Die Daten
Allgemeiner wird es, wenn wir zusätzlich die Daten betrachten. In Kapitel 2 untersucht Wes McKinney die Vornamen aller Neugeborenen seit 1880. Der Datensatz wird von den US-Meldebehörden herausgegeben. Dieser Datensatz ist geschickt ausgewählt, denn er ist erstens aufgeräumt und dadurch gut für Untersuchungen zugänglich. Zweitens ist der Datensatz inhaltlich interessant. Um nur ein Beispiel zu nennen, betrachten wir die Geburtenstatistik für den Vornamen „Madonna“:
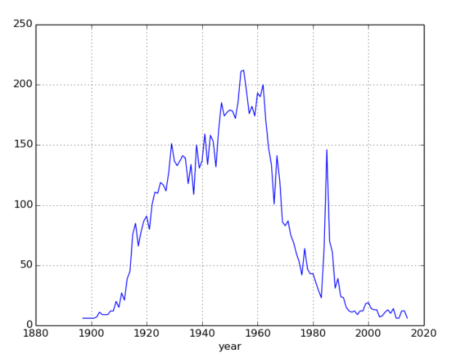
Figure 1: number of US babies named ‘Madonna’
Na, was glauben Sie, in welchem Jahr die Hitsingle „Like a Virgin“ erschienen ist?
Ein qualitativ hochwertiger Datensatz wie dieser macht die Technologie austauschbar. Zum Beispiel untersuchen meine Kursteilnehmer regelmäßig den Datensatz von Babynamen in Python. Mit den Einsteigern verwende ich aber reguläre Python-Funktionen anstelle von pandas, um erst einmal die Grundprinzipien der Sprache zu lernen.
Wes McKinney präsentiert in seinem Buch in jedem Kapitel einen anderen spannenden Datensatz: Spenden für Präsidentschaftskandidaten, Erdbebenopfer auf Haiti, Bestandteile von Nahrungsmitteln und viele mehr. Reichlich Material also, das sich untersuchen lässt, egal mit welcher Technologie.
Die Problemstellung
Für den Lernenden stellt sich die Frage, warum er sich mit den Daten und der Technologie beschäftigen soll. Diese Frage wird durch eine gut gewählte Problemstellung beantwortet. In „Datenanalyse mit Python“ finden sich zahlreiche Beispiele dafür:
- Wie viele Geburten gab es im letzten Jahr insgesamt?
- Sind die Vornamen in den letzten 100 Jahren vielfältiger geworden?
- Wie haben sich die Endbuchstaben von Vornamen verändert?
Wem das nicht ausreicht, kann einmal untersuchen, ob sich Game of Thrones auf die Namenswahl werdender Eltern ausgewirkt hat.
Eine gut gewählte Problemstellung beflügelt die intrinsische Motivation von Lernenden und Lehrenden gleichermaßen, egal ob im Seminarraum oder zu Hause mit einem Buch vor der Nase. Für den Lehrenden bietet sie noch einen weiteren Vorteil: Aus einer Problemstellung lassen sich leicht Trainingseinheiten generieren, die an Bedürfnisse und Fähigkeiten der Lernenden angepasst sind. Für mich funktioniert eine gute Problemstellung als Makefile einer Trainingseinheit. Zum Beispiel habe ich aus den Problemstellungen zu Babynamen einen kompletten Kurstag zu MS Excel generiert. Dass dies mit einem Buch zu einer Python-Bibliothek möglich ist, stellt für mich die universelle Anwendbarkeit dieses technischen Textes unter Beweis.
Wer Datenanalyse mit Python betreibt, kommt im Moment an pandas kaum vorbei. Der eigentliche Verdienst des Buches ist für mich aber, dass der Leser über Problemstellungen und geschickt gewählte Datensätze an Prinzipien der Datenanalyse herangeführt wird, die über die Technologie hinaus gehen. Aus meiner Sicht sind diese universell.
Über den Autor:
Kristian Rother ist professioneller Trainer und Python-Programmierer aus Berlin. Für O’Reilly hat er die Bücher „Einführung in Data Science“ sowie gemeinsam mit Christian Tismer „Datenanalyse mit Python“ übersetzt. Mehr zu Kristian Rother findet Ihr auch auf academis.eu.
Pingback: Geburtstag: "Datenintensive Anwendungen designen" und "Datenanalyse mit Python" - oreillyblog